


เมื่อกราฟราคาเด้งกลับท่ามกลางข่าวเศรษฐกิจและความผันผวนที่ดูไม่มีเหตุผล คุณอาจรู้สึกว่าเดาทางตลาดด้วยประสบการณ์และข่าวสารวันต่อวันไม่พอแล้ว นี่คือจุดที่ Big Data เข้ามาเปลี่ยนเกม เพราะข้อมูลปริมาณมหาศาลจากหลายแหล่งช่วยเปิดเผยสัญญาณที่สายตามนุษย์มองไม่เห็นในทันที
การรวมกันของข้อมูลคำสั่งซื้อ ข้อมูลปริมาณการเทรด และสตรีมข่าวแบบเรียลไทม์ทำให้สามารถสแกนและตีความ เทรนด์ตลาดฟอเร็กซ์ ในมุมที่ต่างออกไป การวิเคราะห์เชิงปริมาณกับชุด ข้อมูลฟอเร็กซ์ ขนาดใหญ่ช่วยลดเสียงรบกวนและเพิ่มความชัดเจนในการตัดสินใจ โดยเฉพาะเมื่อเทรนด์สั้นๆ ประสานกับสัญญาณเชิงโครงสร้างระยะยาว
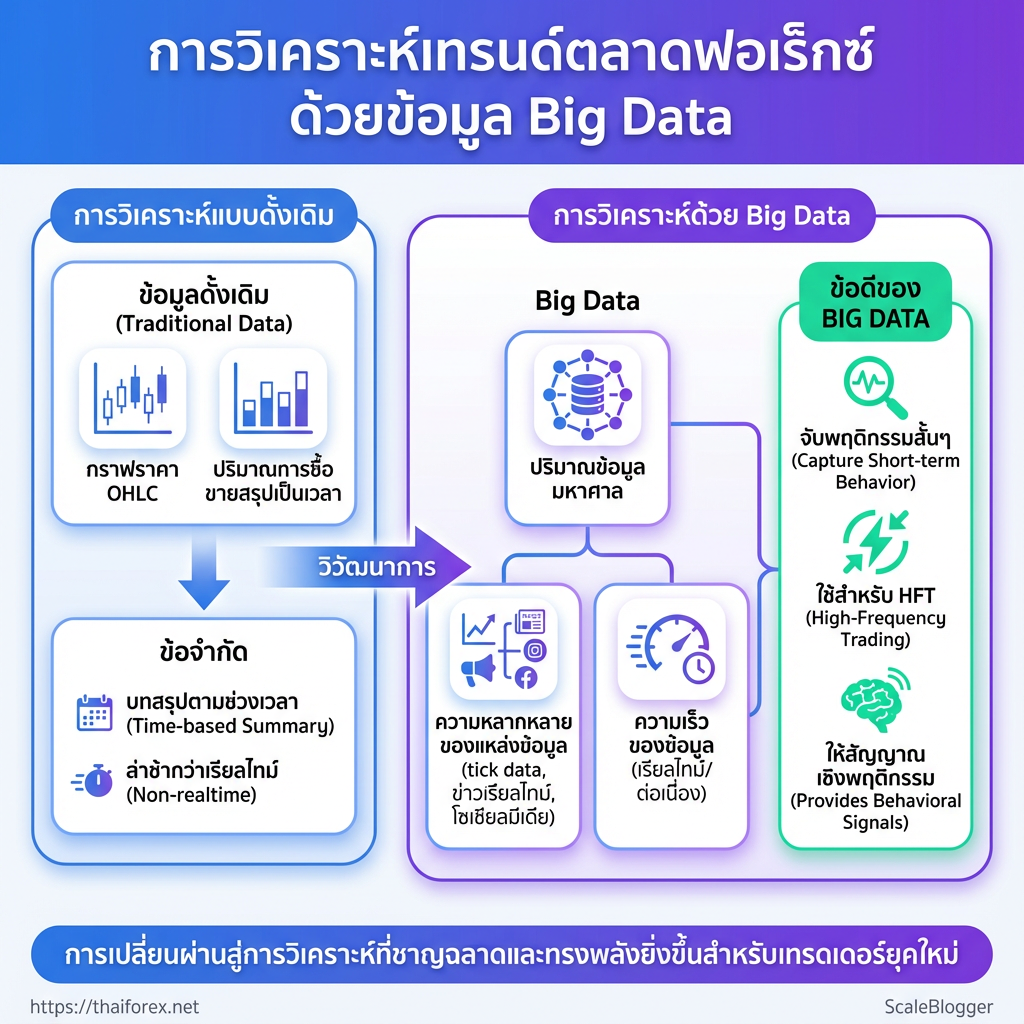
การวิเคราะห์: ทำความเข้าใจว่า “การวิเคราะห์ Big Data” คืออะไร
การวิเคราะห์ Big Data ในบริบทของฟอเร็กซ์คือการใช้ข้อมูลปริมาณมาก หลากหลาย และมักมีความเร็วสูง เพื่อนำมาสร้างสัญญาณเทรดหรือเข้าใจพฤติกรรมตลาดอย่างละเอียด การวิเคราะห์ประเภทนี้ไม่ได้หยุดอยู่ที่กราฟราคาแบบดั้งเดิม แต่ผสานข้อมูลจากหลายแหล่ง เช่น tick data ข้อมูลคำสั่งซื้อขายเชิงลึก ข่าวเรียลไทม์ และสัญญาณจากโซเชียลมีเดีย เพื่อจับภาพความเคลื่อนไหวที่สั้นและซับซ้อนมากขึ้น
การวิเคราะห์ Big Data: การประมวลผลและวิเคราะห์ชุดข้อมูลขนาดใหญ่จากหลายแหล่ง เพื่อค้นหารูปแบบ ความสัมพันธ์ และสัญญาณที่ใช้ตัดสินใจเทรด
ข้อมูลแบบดั้งเดิม: ข้อมูล OHLC, ปริมาณการซื้อขายที่สรุปเป็นเวลา ซึ่งเหมาะกับการวิเคราะห์เชิงเทคนิคแบบคลาสสิก
ข้อมูลแบบ Big Data: tick/order book แบบเรียลไทม์, ฟีดข่าวแบบสตรีม, ข้อมูลเศรษฐกิจมหภาคระดับละเอียด, ข้อความโซเชียลที่ผ่านการทำ NLP
คุณสมบัติสำคัญที่ทำให้เป็น Big Data ปริมาณ: ข้อมูลมีขนาดใหญ่ เช่น ปีของ tick สำหรับคู่สกุลเงินหลัก ความหลากหลาย: แหล่งข้อมูลหลายประเภท (ตัวเลข ข่าว ข้อความเสียง) * ความเร็ว: ข้อมูลเข้ามาแบบเรียลไทม์หรือต่อเนื่อง
เปรียบเทียบประเภทข้อมูล (ดั้งเดิม vs Big Data) ที่เทรดเดอร์ใช้ในฟอเร็กซ์
| ประเภทข้อมูล | ตัวอย่าง | ข้อดี | ข้อจำกัด |
|---|---|---|---|
| ข้อมูลราคาแบบ OHLC | รายชั่วโมง/รายวันจาก MetaTrader history | เหมาะกับเทคนิคอลทั่วไป, เข้าใจง่าย | สูญเสียความละเอียดของเหตุการณ์สั้นๆ |
| Tick/Order Book | tick data, ความลึกบันทึกคำสั่ง (Level II) |
จับพฤติกรรมสั้นๆ, ใช้สำหรับ HFT/market microstructure | ขนาดไฟล์ใหญ่, ต้องการ latency ต่ำ |
| ข่าวเศรษฐกิจ / ปฏิทินข่าว | ตัวเลขการจ้างงาน, ดอกเบี้ยจากการประชุมธนาคารกลาง | ให้มุมมองพื้นฐานที่ขับเคลื่อนราคา | ต้องแยกเสียงรบกวน-ข่าวปลอม |
| ข้อมูลโซเชียลมีเดีย | Twitter sentiment, Reddit threads | สัญญาณเชิงพฤติกรรม, คาดการณ์แรงเทขาย/ซื้อเฉียบพลัน | ต้องการ NLP, เสียงเกินจริงสูง |
| ข้อมูลทางเศรษฐกิจขนาดใหญ่ | ข้อมูลการเดินทางคน, ดัชนีการค้ารายวัน | ให้สัญญาณเชิงเศรษฐกิจเรียลไทม์ | ต้องการการทำความสะอาดและการรวมหลายแหล่ง |
การผสานข้อมูลเหล่านี้ช่วยให้โมเดลจับจังหวะความผิดปกติได้ดีกว่าการพึ่งพา OHLC อย่างเดียว ตัวอย่างเช่นการร่วมวิเคราะห์ order book กับฟีดข่าวสามารถเปิดโอกาสในการตั้งคำสั่งล่วงหน้าก่อนการแกว่งตัวครั้งใหญ่ในช่วงประกาศตัวเลขเศรษฐกิจ
การวิเคราะห์ Big Data ทำให้การตัดสินใจเทรดมีมิติใหม่ แต่ต้องลงทุนในโครงสร้างข้อมูลและกลยุทธ์การกรองข้อมูล เพื่อให้สัญญาณที่ได้มีคุณภาพและนำไปใช้ได้จริงในบัญชีเทรดทั้งแบบเดโมและจริง.
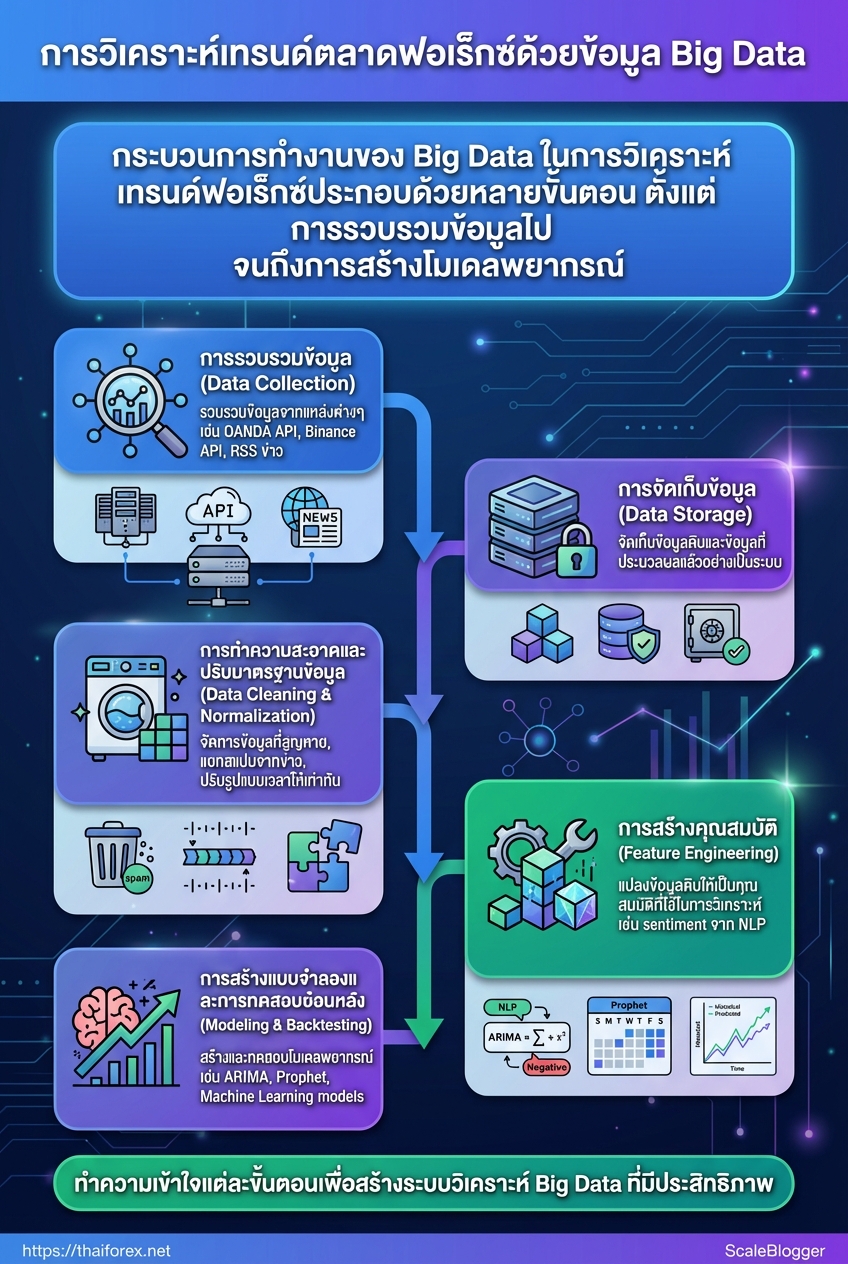
กลไกการทำงาน: Big Data ทำงานอย่างไรในการวิเคราะห์เทรนด์ฟอเร็กซ์
Big Data ในการวิเคราะห์เทรนด์ฟอเร็กซ์คือการเปลี่ยนข้อมูลจากหลายแหล่งให้กลายเป็นสัญญาณที่ใช้ตัดสินใจได้จริง โดยทั่วไปจะมี pipeline ขั้นพื้นฐานที่ทำให้ข้อมูลดิบกลายเป็นโมเดลพยากรณ์และสัญญาณเทรดได้อย่างเป็นระบบ การออกแบบ pipeline ให้เรียบง่าย แต่ออกแบบมารับมือกับความไม่แน่นอนของข้อมูลฟอเร็กซ์ จะช่วยลดเสียงรบกวนและเพิ่มความเชื่อมั่นในการตัดสินใจ
- Data Collection
- Data Storage
- Data Cleaning & Normalization
- Feature Engineering
- Modeling & Backtesting
แต่ละขั้นตอนมีรายละเอียดและกับดักที่ต่างกัน — ข้อมูลราคาเรียลไทม์อาจสูญหายจากการขาดการเชื่อมต่อ, ข้อมูลข่าวและโซเชียลมีเดียต้องแยกเสียงสแปมออก, ส่วนข้อมูลเศรษฐกิจมักมีความหน่วงและรูปแบบเวลาไม่เท่ากัน วิธีแก้คือใช้การล็อกเวลา (time-stamping), การทำ resampling และการเก็บ raw feed แยกจาก processed feed เพื่อย้อนกลับเมื่อจำเป็น
เทคนิควิเคราะห์ยอดนิยมที่นำไปใช้จริง
Sentiment analysis: วิเคราะห์ความรู้สึกจากข่าวและโซเชียลโดยใช้ NLP เพื่อสร้างสัญญาณชี้นำตลาด Time-series models: ใช้ ARIMA, Prophet, และ Exponential Smoothing สำหรับพยากรณ์ระยะสั้นถึงกลาง Machine Learning: Random Forest, XGBoost, หรือ LSTM เพิ่มความซับซ้อน แต่ต้องระวัง overfitting* และให้ความสำคัญกับ cross-validation แบบ time-series
การใช้งานจริงมักผสมกัน: sentiment ทำหน้าที่เป็น signal filter, time-series ให้ baseline forecast, ML เพิ่ม nonlinear interaction ระหว่าง features เช่น volatility, volume, economic surprise.
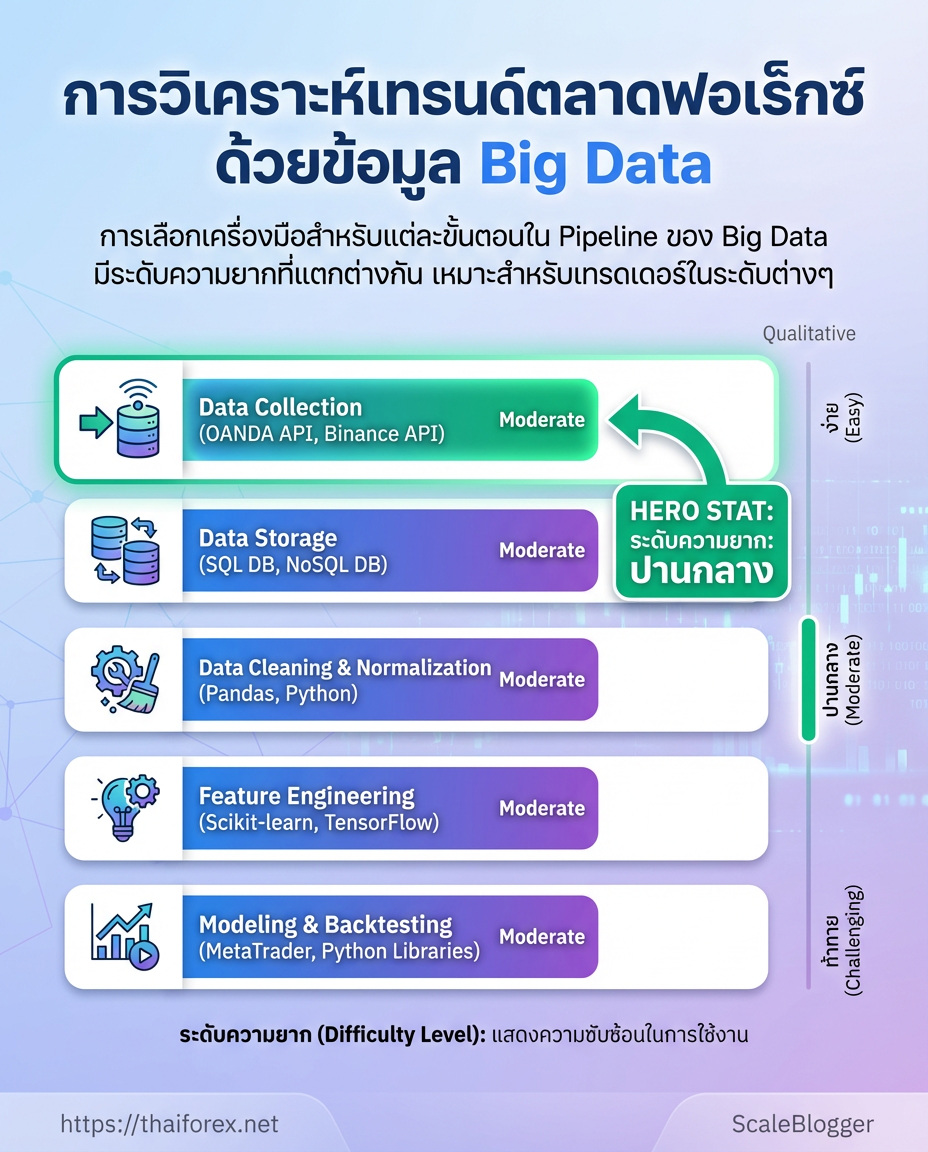
แสดงเครื่องมือ/เทคโนโลยีที่ใช้ในแต่ละขั้นตอนของ pipeline และข้อดีข้อจำกัดสำหรับเทรดเดอร์
| ขั้นตอน | ตัวอย่างเครื่องมือ/แพลตฟอร์ม | ระดับความยาก | เหมาะกับใคร |
|---|---|---|---|
| Data Collection | OANDA API, Alpha Vantage, Binance API, RSS ข่าว | ปานกลาง | เทรดเดอร์ที่ต้องการข้อมูลเรียลไทม์และฟรี/ถูก |
| Data Storage | PostgreSQL, InfluxDB, AWS S3, Google BigQuery | สูง | ทีมที่เก็บข้อมูลปริมาณมากและต้องการสเกล |
| Data Cleaning | Python (pandas), R (tidyverse), OpenRefine | ปานกลาง | ผู้ที่ทำ ETL ด้วยสคริปต์เอง |
| Feature Engineering | Python (ta-lib, numpy), SQL, Spark | สูง | นักวิเคราะห์ที่สร้างฟีเจอร์เชิงเทคนิค/เศรษฐกิจ |
| Modeling/Backtesting | scikit-learn, TensorFlow, Prophet, Backtrader, Zipline | สูง | นักพัฒนาอัลกอริทึมและผู้ทดสอบกลยุทธ์ |
Key insight: ตารางชี้ให้เห็นว่าผู้เริ่มต้นสามารถเริ่มจาก API ฟรีและ storage แบบ SQL ได้ แต่เมื่อขยายการวิเคราะห์เป็น Big Data จำเป็นต้องย้ายไปยังระบบสเกลได้เช่น S3/BigQuery และใช้เครื่องมือ backtesting ที่รองรับเวลา/ตลาดจริงเพื่อป้องกัน overfitting.
การออกแบบ pipeline ที่เหมาะสมทำให้สัญญาณจากข้อมูลข่าวและราคาเชื่อมกันได้อย่างมีเหตุผล และการเลือกเทคนิคที่พอดีจะช่วยให้ผลลัพธ์ใช้งานได้จริงในพอร์ตเทรดและการจัดการความเสี่ยงอย่างมีประสิทธิภาพ.
ทำไมการวิเคราะห์ Big Data สำคัญต่อเทรนด์ตลาดฟอเร็กซ์
การวิเคราะห์ Big Data ช่วยให้เห็นสัญญาณเชิงปริมาณและพฤติกรรมตลาดที่ซ่อนอยู่ในข้อมูลจำนวนมหาศาลก่อนที่ผู้เล่นรายใหญ่จะเปลี่ยนกลยุทธ์ ผู้ที่ใช้ข้อมูลจากหลายแหล่ง — ข่าวเศรษฐกิจ, บันทึกคำสั่งซื้อ, โวลุมบนแพลตฟอร์มต่าง ๆ และสัญญาณโซเชียล — จะสามารถจับแนวโน้มขาขึ้น/ขาลงได้เร็วขึ้นและปรับตำแหน่งความเสี่ยงได้อย่างเป็นระบบมากขึ้น ซึ่งหมายถึงการตัดสินใจที่แม่นยำขึ้นและการจัดการความเสี่ยงที่มีประสิทธิผลกว่าเดิม
การใช้งานจริงมักรวมหลายมิติของข้อมูล: ข้อมูลเชิงเวลา: เวลา-ซีรีส์จากราคาและโวลุม เพื่อจับจังหวะความผิดปกติ ข้อมูลเชิงเหตุการณ์: ข่าวสำคัญ, ประกาศนโยบายการเงิน, ตัวเลขเศรษฐกิจ ข้อมูลพฤติกรรม: คำสั่งซื้อและการถือสถานะจากตลาดสาธารณะและโบรกเกอร์ ข้อมูลโซเชียล: ความคิดเห็นและแนวโน้มจากทวีต ฟอรัม และข่าวสื่อมวลชน
ข้อดีและโอกาสที่ชัดเจนคือการตรวจจับแนวโน้มก่อนผู้เล่นรายใหญ่, การเพิ่มความแม่นยำเมื่อรวมแหล่งข้อมูลหลายมิติ, และการปรับระบบบริหารความเสี่ยงให้ตอบสนองแบบเชิงปริมาณ เช่น การใช้สัญญาณร่วมกันเพื่อปรับขนาดล็อตหรือปิดสถานะอัตโนมัติเมื่อตรงตามเงื่อนไขความเสี่ยงที่กำหนด
ขณะเดียวกันมีข้อจำกัดที่ต้องระวัง เช่น ต้นทุนโครงสร้างพื้นฐาน, ความเสี่ยงจากสัญญาณเท็จ และการ overfit โมเดลซึ่งทำให้ผลการทดสอบย้อนหลังดีแต่ล้มเหลวในตลาดจริง การทดสอบย้อนหลัง (backtest) และการตรวจสอบผลแบบต่อเนื่องเป็นสิ่งจำเป็นเพื่อป้องกันการตัดสินใจจากข้อมูลที่หลอกลวง
เปรียบเทียบข้อดี/ข้อเสียของการใช้ Big Data สำหรับเทรดเดอร์รายย่อย vs สถาบัน
| ประเด็น | เทรดเดอร์รายย่อย | สถาบัน/โบรกเกอร์ | ทางออก/คำแนะนำ |
|---|---|---|---|
| ต้นทุนการจัดเก็บ | จำกัด; บริการคลาวด์ราคาแพงเมื่อขยาย | มีโครงสร้างพื้นฐานเฉพาะทาง | ใช้ cloud credits แบบจ่ายตามใช้จริง หรือแชร์ข้อมูลผ่านแพลตฟอร์มข้อมูล |
| การเข้าถึงข้อมูลเชิงลึก | ข้อมูลบางประเภทถูกจำกัดหรือมีค่าใช้จ่ายสูง | เข้าถึงข้อมูลเชิงลึกและ feed แบบเรียลไทม์ | สมัครข้อมูลจาก data vendors แบบแบ่งชั้น หรือตรวจสอบ feed ฟรีก่อนจ่าย |
| ทรัพยากรบุคคล/ความเชี่ยวชาญ | ขาดทีมวิทยาศาสตร์ข้อมูล | ทีมเฉพาะด้านและนักวิเคราะห์ | เรียนรู้พื้นฐานด้วยบัญชีเดโม, ใช้โมเดลสำเร็จรูปหรือคอร์สออนไลน์ |
| ความเร็วในการประมวลผล | ประมวลผลช้ากว่าเมื่อปริมาณเพิ่ม | ระบบ low-latency สำหรับ HFT และการบริหารความเสี่ยง | ปรับกลยุทธ์เป็นสัญญาณเชิงกลยุทธ์แทน HFT หากไม่มี latency ต่ำ |
| การบริหารความเสี่ยง | ยากเมื่อต้องตอบสนองต่อเหตุการณ์ตลาดเร็ว | ระบบอัตโนมัติและ stress-test ต่อเนื่อง | ตั้ง stop-loss เชิงสัญญาณและทดสอบย้อนหลังก่อนใช้งานจริง |
Market leaders และผู้ให้บริการข้อมูลมีแพ็กเกจที่แตกต่างกัน; เริ่มจากทดลองด้วยข้อมูลฟรีหรือบัญชีเดโมก่อนลงทุนระบบจริง เช่น การฝึกกับ บัญชีเดโม ช่วยลดความเสี่ยงเบื้องต้นอย่างเห็นได้ชัด การวิเคราะห์ Big Data จึงไม่ใช่แค่เรื่องเทคโนโลยี แต่เป็นการผสานข้อมูล ความรู้ และการบริหารความเสี่ยงเข้าด้วยกัน เพื่อให้การเทรดในระยะยาวมีความสม่ำเสมอและยั่งยืนมากขึ้น
การนำ Big Data มาใช้ต้องพร้อมลงทุนด้านเวลาและทดสอบอย่างจริงจัง แต่เมื่อทำถูกวิธี มันจะกลายเป็นช่องทางที่ช่วยให้ตัดสินใจได้เร็วขึ้นและมีความสม่ำเสมอมากขึ้นในการเทรนด์ตลาดฟอเร็กซ์.
การประยุกต์ใช้งานจริงและตัวอย่างกรณีศึกษา
การใช้งานข้อมูลเชิงลึกจากข้อความ ตลาดคำสั่ง และข้อมูลมหภาค สามารถเปลี่ยนจากแนวคิดเป็นสัญญาณเทรดที่จับต้องได้ได้จริง ในบริบทฟอเร็กซ์ การผสานสามแหล่งนี้ช่วยให้มองเห็นแรงขับเคลื่อนราคาที่ต่างกัน — อารมณ์ตลาด, การไหลของสภาพคล่อง, และตัวเร่งจากนโยบายหรือข้อมูลเศรษฐกิจ
กรณีตัวอย่างที่ 1: การใช้ Sentiment Analysis ตีความข่าว
แหล่งข้อมูลที่ใช้: ข่าวจากสำนักใหญ่, Twitter, ฟอรัมการเงิน วิธีแปลงข้อความเป็นตัวชี้วัดเชิงปริมาณ: ใช้ tokenization และ sentiment scoring ให้คะแนนแต่ละข้อความเป็น -1 ถึง +1 แล้วคำนวณค่าเฉลี่ยถ่วงน้ำหนักตามแหล่งและเวลา ตัวอย่างผลลัพธ์และข้อจำกัด: เมื่อตรวจพบคะแนนเชิงบวกสูงต่อสกุลเงินหนึ่งในชั่วโมงหลังประกาศผลประกอบการ ค่าเฉลี่ยเชิงอารมณ์ขึ้นนำสัญญาณการไหลของเงินทุนสั้น ๆ แต่ข้อจำกัดคือเสียงรบกวนจากบอทและข่าวปลอม ทำให้ต้องใช้การกรองแหล่งข้อมูลและการถ่วงน้ำหนักตามความน่าเชื่อถือของบัญชีหรือสำนักข่าว
กรณีตัวอย่างที่ 2: การวิเคราะห์ Order Flow และ Tick Data
แสดงตัวอย่างรูปแบบ Tick/Order Flow ที่พบบ่อยและการตีความเป็นสัญญาณเทรด
| รูปแบบ Tick | ลักษณะราคา/ปริมาณ | การตีความ | ตัวอย่างการตอบสนอง |
|---|---|---|---|
| Large Buy Sweep | ราคากระโดดขึ้นพร้อม volume ขนาดใหญ่ | สภาพคล่องถูกกวาดหน้า อาจเป็นสัญญาณสวิงขึ้น | เข้าซื้อระยะสั้นหรือขึ้นขนาด position |
| Order Book Imbalance | ส่วนต่าง bid/ask มีความไม่สมดุลชัดเจน | ความกดดันซื้อ/ขายล่วงหน้า | รอ breakout ตามทิศทาง imbalance |
| Sudden Volume Spike | ปริมาณเทรดพุ่งโดยไม่เปลี่ยนเทรนด์ราคา | การเข้ามาของผู้เล่นขนาดใหญ่ | วาง stop tight และตาม momentum |
| Persistent Small Orders | คำสั่งขนาดเล็กต่อเนื่องที่ราคาแน่น | การสะสมตำแหน่งแบบละเอียด | คาดการณ์การ breakout ช้า ๆ |
| Cross-market arbitrage signal | Tick เดียวกันจากคู่สกุลต่างตอบสนองล่าช้า | สัญญาณโอกาส arbitrage ข้ามตลาด | ส่งคำสั่งสั้น ๆ เพื่อเก็บ spread |
Key insight: การอ่าน order flow ช่วยจับจังหวะสภาพคล่องจริง แต่ต้องทดสอบกับ slippage และ latency ในแพลตฟอร์มจริงก่อนใช้งาน
กรณีตัวอย่างที่ 3: กลยุทธ์ขับเคลื่อนด้วย Macro Big Data
ตัวชี้วัดที่สำคัญต่อสกุลเงิน: GDP growth momentum, Fed rate expectations, PMI, CPI surprise 1. รวบรวมชุดข้อมูลรายไตรมาสและรายเดือนจากแหล่งที่เชื่อถือได้
- สร้าง
z-scoreของแต่ละตัวชี้วัดเพื่อหา ความเบี่ยงเบน จากค่าเฉลี่ยประวัติ - รวมสัญญาณน้ำหนักตามความสำคัญแล้วทดสอบย้อนหลังด้วย rolling window
การทดสอบย้อนหลังต้องรวมการตั้งค่า transaction cost และ stress test ในช่วงเหตุการณ์ extreme เพื่อประเมิน robustness ของสัญญาณ
การรวมสามแนวทางนี้—sentiment, order flow, macro—ช่วยให้ระบบเทรดมีมิติทั้งความเร็วและมุมมองเชิงเหตุผล ที่สำคัญคือการทดสอบและการควบคุมความเสี่ยงต้องมาก่อนเสมอ เพื่อให้สัญญาณที่ได้ใช้งานได้จริงและอยู่รอดในตลาดจริง.
📝 Test Your Knowledge
Take this quick quiz to reinforce what you’ve learned.
การสร้างและทดสอบระบบที่ใช้ Big Data สำหรับเทรนด์ฟอเร็กซ์
การออกแบบระบบ Big Data เพื่อจับเทรนด์ฟอเร็กซ์ต้องเริ่มจากสมมติฐานเชิงธุรกิจก่อนเสมอ: จะใช้สัญญาณไหนเพื่อตัดสินใจเทรด, ผลตอบแทนที่คาดหวังคืออะไร, และข้อจำกัดเชิงความเสี่ยงเป็นอย่างไร จากนั้นค่อยแปลงสมมติฐานเป็นสเปคข้อมูลและเมตริกสำหรับทดสอบ การทำแบบนี้ช่วยให้การพัฒนาโมเดลไม่หลุดกรอบธุรกิจและสามารถประเมินผลได้เชิงปริมาณ
ขั้นตอนสำคัญและแนวปฏิบัติ ตั้งสมมติฐานเชิงธุรกิจ: นิยามสัญญาณ (momentum, volatility, correlation) และสมมติผลตอบแทน/ความเสี่ยง แบ่งข้อมูล time-series อย่างถูกต้อง: หลีกเลี่ยงการรั่วไหลของข้อมูลด้วย rolling windows และการแบ่งตามเวลา ไม่ควรสุ่มแบ่งแบบ i.i.d. walk-forward testing: ปรับพารามิเตอร์บนชุดย้อนหลัง แล้วทดสอบบนหน้าต่างถัดไปซ้ำๆ เพื่อจำลองการใช้งานจริง out-of-sample validation: แยกชุดข้อมูลสุดท้ายไว้สำหรับการตรวจสอบครั้งสุดท้ายหลังปรับแต่งโมเดล * ทดสอบแบบติดเครื่อง (paper trading): รันสัญญาณในบัญชีเดโมเพื่อดูผลกระทบของสลิปเพจและค่าธรรมเนียมจริง
แสดง timeline ของโครงการพัฒนาโมเดล Big Data ตั้งแต่การเก็บข้อมูลจนถึงการ deploy
| เฟส | กิจกรรมหลัก | ประมาณเวลา | ผลลัพธ์ที่คาดหวัง |
|---|---|---|---|
| การเก็บข้อมูล | รวบรวมราคาตลาด, tick data, ข่าว, บันทึกเศรษฐกิจ | 2–6 สัปดาห์ | ฐานข้อมูลดิบครบถ้วน (raw ticks, OHLC, event logs) |
| การทำความสะอาดและเตรียมข้อมูล | การจัดการ missing values, timezone, resampling | 2–4 สัปดาห์ | ข้อมูลเป็น time-series ต่อเนื่องและพร้อมใช้ |
| การสร้างฟีเจอร์และทดสอบแบบติดเครื่อง | สร้าง momentum/volatility features, window stats, label generation | 3–6 สัปดาห์ | ชุดฟีเจอร์พร้อมตั้งสมมติฐานและผลการทดลองเบื้องต้น |
| Backtesting และ Validation | Walk-forward testing, out-of-sample, sensitivity analysis | 4–8 สัปดาห์ | ประสิทธิภาพในหลายช่วงเวลา, รายงานความเสี่ยง |
| Deploy และ Monitoring | Deploy โมเดล, real-time pipeline, dashboard monitoring | 2–4 สัปดาห์ | ระบบรันจริงพร้อม alert สำหรับ drift/decay |
Key insight: ตารางนี้แสดงว่าโปรเจ็กต์ Big Data สำหรับเทรนด์ฟอเร็กซ์มักใช้เวลาหลายเดือน โดยขั้นตอนสำคัญคือการเตรียมข้อมูลและการทดสอบแบบเวลาจริงที่ซ้ำๆ ซึ่งลดความเสี่ยงของการ overfit และช่วยให้การ deploy มีความน่าเชื่อถือมากขึ้น
- ระบุสมมติฐานเชิงธุรกิจและเกณฑ์ความสำเร็จสำหรับสัญญาณ
- สร้าง pipeline เก็บข้อมูลและเซ็ต
feature store - ทำการทดสอบย้อนหลังด้วย
walk-forwardและแยกชุด out-of-sample - รัน paper trading และปรับกลยุทธ์ตามผลการสาธิต
- เปิดใช้งานการมอนิเตอร์แบบเรียลไทม์และกลไก rollback
การจัดการความเสี่ยงและการมอนิเตอร์ กฎ risk management: ตั้ง stop-loss, position sizing rules, และ max drawdown thresholds ชั้นการอนุมัติ: แยกระบบเป็น staging → canary → production พร้อมเกณฑ์ performance ก่อนเลื่อนสถานะ ตรวจจับ data drift: วัดการเปลี่ยนแปลง distribution ของฟีเจอร์ด้วย KS test หรือ EMD เป็นระยะ ตรวจจับ model decay: ติดตามการลดลงของอัตราชนะ, Sharpe ratio, และ latency ของสัญญาณ * มอนิเตอร์แบบเรียลไทม์: ตั้ง alerts เมื่อ violation ของ risk rules หรือ metric degradation เกิดขึ้น
การทดสอบที่เข้มงวดและการมอนิเตอร์ต่อเนื่องช่วยให้ระบบตอบสนองต่อการเปลี่ยนแปลงตลาดและลดโอกาสที่จะปล่อยสัญญาณที่ล้าสมัยออกสู่การใช้งานจริง การเริ่มจากสมมติฐานธุรกิจที่ชัดเจนแล้วทำซ้ำการทดสอบแบบเวลาจริง จะให้ผลลัพธ์ที่ใช้งานได้จริงและปลอดภัยกว่าเพียงแค่ไล่หาโมเดลที่ให้ผลดีบนข้อมูลย้อนหลังเท่านั้น
การทดลองบนบัญชีเดโมก่อนขึ้นจริง เช่นการรันกลยุทธ์ในสภาพแวดล้อมที่เลียนแบบตลาด, จะเป็นอีกชั้นความปลอดภัยที่ควรมีเสมอสำหรับการนำ Big Data ไปใช้กับเทรนด์ตลาดฟอเร็กซ์.
ข้อผิดพลาดที่พบบ่อยและความเข้าใจผิดเกี่ยวกับ Big Data ในฟอเร็กซ์
นักเทรดหลายคนคิดว่าแค่มีข้อมูลจำนวนมากก็จะได้คำตอบที่ดีกว่า แต่ความจริงซับซ้อนกว่า: คุณภาพของข้อมูลมีค่าน้ำหนักมากกว่าปริมาณ เมื่อข้อมูลมี noise, ข้อมูลขาดความสอดคล้อง หรือมีตัวแปรที่ล้าสมัย ก็จะสร้างสัญญาณเท็จและทำให้โมเดลหลงทางได้ง่าย
ความเชื่อผิดที่ 1: ‘ข้อมูลมากเท่ากับผลลัพธ์ที่ดีขึ้นเสมอ’
มีข้อมูลเยอะแต่เต็มไปด้วยข้อผิดพลาด เช่น timestamps ผิด, spreads ไม่รวมค่าคอมมิชชั่น, หรือข้อมูลจากแหล่งที่มีเวลาต่างกัน จะสร้าง pattern ปลอมที่ดูน่าเชื่อถือแต่ไม่ยืดหยุ่นในตลาดจริง ตัวอย่างเช่น การใช้ tick data จากโบรกเกอร์เดียวโดยไม่ปรับ spread อาจทำให้สัญญาณความผันผวนสูงเกินจริง
แนวทางคัดกรองและทำความสะอาดข้อมูล 1. ตรวจหา missing values และ outliers แล้วจัดการแยกประเภทก่อนใช้งาน 2. ปรับเวลาให้เป็น UTC และตรวจสอบความสอดคล้องของ timestamp 3. ลบหรือแก้ไข duplicate records และ normalized ค่า price/volume 4. ตรวจสอบการเปลี่ยนแปลง microstructure เช่น spread spikes และ session gaps
การทำข้อมูลให้สะอาดและมี metadata ชัดเจนสำคัญกว่าการซื้อข้อมูลเพิ่มอย่างไร้แผน
ความเชื่อผิดที่ 2: ‘โมเดล ML จะทำนายตลาดได้แม่นยำเสมอ’
โมเดลเรียนรู้จากข้อมูลที่ผ่านมา แต่ตลาดมีองค์ประกอบสุ่มและ regime shifts ทำให้ข้อจำกัดเชิงสถิติ เช่น overfitting และความไม่เป็นสเตชันของ series เป็นปัญหาหลัก การทดสอบเพียงแค่ train/test split แบบสุ่มมักไม่เพียงพอ
การทดสอบเชิงสถิติและการตีความผล Backtest แบบ walk-forward: ลดการรั่วของข้อมูลอนาคต ประเมินด้วย metrics หลายมิติ: เช่น drawdown, Sharpe, และความเสถียรของพารามิเตอร์ * ทดสอบความทนทานของสัญญาณ: ฝัง noise ลงในข้อมูลเพื่อตรวจจับ robustness
การใช้งาน ML อย่างรับผิดชอบควรผสมกับกฎการจัดการความเสี่ยงและทดสอบในบัญชีเดโมก่อนใช้งานจริง — นี่เป็นขั้นตอนที่เรียนรู้ได้จากการฝึกในสภาพแวดล้อมปลอดภัยก่อนนำไปใช้จริง
การระวังสองความเข้าใจผิดนี้ช่วยให้แผนการวิเคราะห์ Big Data ในฟอเร็กซ์มีความเป็นจริงและนำไปใช้ได้จริงมากขึ้น, และลดโอกาสเสียเงินจากสัญญาณปลอมหรือโมเดลที่ดูดีบนกระดาษแต่ล้มเหลวในตลาดจริง.
เริ่มต้นใช้งาน: เครื่องมือและทรัพยากรสำหรับเทรดเดอร์ไทย
การเริ่มต้นด้วยเครื่องมือที่ถูกต้องช่วยลดเวลาการเรียนรู้และลดความเสี่ยงได้ทันที ทั้งแหล่งข้อมูลตลาด เครื่องมือวิเคราะห์ และแพลตฟอร์มเชื่อมต่อกับโบรกเกอร์ ควรเลือกตามงบ ขอบเขตข้อมูล และความต้องการเชิงกลยุทธ์ก่อนลงทุนจริง
แหล่งข้อมูลและผู้ให้บริการข้อมูลที่ควรพิจารณา
- ข้อมูลปฏิทินเศรษฐกิจ: ให้ข่าวเศรษฐกิจและเวลาปล่อยตัวเลขสำคัญ
- News API และบริการข่าว: ข่าวเชิงเหตุการณ์ช่วยจับเทรนด์ความเสี่ยงระยะสั้น
- Social data: ความเห็นสาธารณะช่วยประเมินความเชื่อมั่นตลาดแบบเรียลไทม์
- Tick/Level-1 data vendors: จำเป็นสำหรับเทรดเดอร์ความถี่สูงและการทดสอบกลยุทธ์ที่แม่นยำ
- ฐานข้อมูลเชิงประวัติ (Big Data): สำหรับการวิเคราะห์ backtest และการเรียนรู้เครื่อง
การเลือก vendor ให้พิจารณา: latency ต่ำสำหรับการทำงานเรียลไทม์, coverage ของคู่สกุลและช่วงเวลา, และ cost ที่สอดคล้องกับแผนการเทรด ตลาดมีตัวเลือกตั้งแต่ฟรีจนถึงค่าบริการรายเดือนสูง สำหรับเทรดเดอร์งบจำกัด ให้เริ่มจากแหล่งฟรี/มีรุ่นทดลอง แล้วอัปเกรดเมื่อกลยุทธ์พิสูจน์ผล
รวมรายการแหล่งข้อมูลและเครื่องมือที่แนะนำ พร้อมระดับราคาและความเหมาะสมสำหรับผู้เริ่มต้น-ผู้เชี่ยวชาญ
| ทรัพยากร/เครื่องมือ | ประเภท | ระดับราคา | เหมาะสำหรับ |
|---|---|---|---|
| Investing.com Economic Calendar | ปฏิทินเศรษฐกิจ | ฟรี / พรีเมียม | ผู้เริ่มต้น-กลาง |
| Reuters / NewsAPI | ข่าวเชิงเหตุการณ์ (API) | ฟรีจำกัด / พรีเมียม | กลาง-สูง |
| Twitter API | Social data (Sentiment) | ฟรีจำกัด / แพ็กเกจชำระ | กลาง-สูง |
| TickData (ผู้ให้บริการ Tick) | Tick/Level-1 data | รายงานราคา / ตามขอบเขต | สูง (HFT/backtest) |
| Backtrader | แพลตฟอร์ม Backtesting (open-source) | ฟรี | ผู้เริ่มต้น-กลาง |
| MetaTrader 4/5 | แพลตฟอร์มเทรดครบวงจร | ฟรี (โบรกฯ) | ผู้เริ่มต้น-กลาง |
| TradingView | แผนภูมิ & สแกนสัญญาณ | ฟรี / Pro $/mo | ผู้เริ่มต้น-สูง |
| Quandl / Nasdaq Data Link | ฐานข้อมูลเชิงประวัติ | ฟรีบางชุด / พรีเมียม | กลาง-สูง |
การวิเคราะห์: ตารางแสดงการกระจายตัวของแหล่งข้อมูลจากฟรีจนถึงระดับมืออาชีพ สำหรับคนงบน้อย ให้ผสม Investing.com, Backtrader และ TradingView รุ่นฟรีก่อน จากนั้นค่อยอัปเกรดไปยัง NewsAPI หรือ TickData เมื่อกลยุทธ์ต้องการความแม่นยำเชิงเวลา
แพลตฟอร์มและการเชื่อมต่อกับบัญชีโบรกเกอร์
- ติดตั้งและทดสอบในบัญชี
เดโมก่อนเชื่อมของจริง - ตรวจสอบการเชื่อมต่อ
API keyและใช้ช่องทางเข้ารหัส (SSL/TLS) - เปิดสิทธิ์การอ่าน-เขียนเฉพาะที่จำเป็นและทดสอบคำสั่งเล็ก ๆ
การเรียนรู้ผ่านบัญชีเดโม: การฝึกกับเดโมช่วยให้จับจังหวะการส่งคำสั่งและการตั้ง stop-loss ได้โดยไม่เสียเงินจริง — ถ้าต้องการคู่มือการใช้บัญชีเดโม สามารถใช้หลักการเดียวกับหลักสูตรพื้นฐานที่เน้นการจัดการความเสี่ยง
การเลือกเครื่องมือที่เหมาะสมเริ่มจากเป้าหมายการเทรด งบประมาณ และความต้องการข้อมูล เมื่อระบบพื้นฐานเสถียร การพัฒนาและขยายเครื่องมือจะกลายเป็นการลงทุนอย่างมีเหตุผลต่อผลลัพธ์การเทรดของคุณ.
แนวทางปฏิบัติและกลยุทธ์สำหรับผู้เริ่มต้น
เริ่มจากพื้นฐานข้อเดียวก่อน: เรียนรู้ผ่านการทำจริงทีละขั้นตอน โดยใช้ข้อมูลที่เข้าถึงได้และเครื่องมือทดลองก่อนนำเงินจริงเข้าไปเกี่ยวข้อง การทำงานแบบทดลอง (incremental testing) ช่วยลดความเสี่ยงและสร้างความเชื่อมั่นเชิงปฏิบัติ มากกว่าการจำสูตรสำเร็จจากที่อื่น
การปฏิบัติที่แนะนำมีสองแกนหลัก: ฝึกกระบวนการวิเคราะห์ข้อมูลและออกแบบกฎการเทรดที่เข้าใจได้ รายละเอียดต้องชัดเจน — นิยามว่าจะแท็กสัญญาณอย่างไร จะตัดขาดทุนเมื่อไหร่ แล้วทดสอบบนข้อมูลเดโมก่อน ใช้บัญชีเดโมหรือเงินจำนวนน้อยเพื่อตรวจสอบสมมติฐานทีละส่วน ตัวอย่างเช่น ถ้าสมมติฐานคือ “การเบรกของค่าเฉลี่ยเคลื่อนที่ 20 วันให้ผลดี” ให้ทดสอบเฉพาะสัญญาณนี้กับสัญญาณการจัดการความเสี่ยงก่อนขยายเป็นพอร์ตจริง
เครื่องมือที่เข้าถึงได้ เช่น แพลตฟอร์มกราฟฟรี, ข้อมูลราคาย้อนหลังจากโบรกเกอร์, และสเปรดชีตสำหรับการทำความสะอาดข้อมูล จะช่วยให้เริ่มได้เร็ว ตัวอย่างเช่น การดาวน์โหลดข้อมูล CSV แล้วใช้ pandas หรือ Excel ทำการกรองและสร้างตัวชี้วัดพื้นฐานก่อนนำไปสู่ Backtest เบื้องต้น
- เลือกแหล่งข้อมูลที่เชื่อถือได้ (ราคา, ปริมาณ, วอลาทิตี้)
- ดาวน์โหลดหรือเชื่อมต่อข้อมูลเข้ากับเครื่องมือวิเคราะห์
- ตรวจสอบความสมบูรณ์ของข้อมูลและแก้ missing values
- ทำความสะอาดข้อมูล (ปรับ timezone, กรอง outlier)
- สร้างฟีเจอร์พื้นฐาน เช่น ค่าเฉลี่ยเคลื่อนที่และ ATR
- เขียนกฎการเข้า-ออกแบบเรียบง่ายและชัดเจน
- Backtest เบื้องต้นบนข้อมูลย้อนหลัง
- วิเคราะห์ผล: อัตราชนะ, อัตรความเสี่ยง/ผลตอบแทน, Max Drawdown
- ปรับปรุงสมมติฐานทีละส่วนและทดสอบซ้ำ
- เริ่มเทรดด้วยเงินทุนน้อยและมอนิเตอร์ผลอย่างใกล้ชิด
เช็คลิสต์การดำเนินการพร้อมระดับความยากและเวลาโดยประมาณ
| ขั้นตอน | การดำเนินการ | ระดับความยาก | เวลาที่คาดหวัง |
|---|---|---|---|
| เลือกแหล่งข้อมูล | เลือกฟีดราคา/โบรกเกอร์ เช่น tick/candles | ต่ำ | 1-2 ชั่วโมง |
| ดาวน์โหลด/เชื่อมต่อข้อมูล | ดึง CSV หรือ API จากโบรกเกอร์ | ปานกลาง | 1-3 ชั่วโมง |
| ตรวจสอบข้อมูลเบื้องต้น | เช็ค missing/duplicates | ต่ำ | 30-60 นาที |
| ทำความสะอาดข้อมูล | ปรับ timezone, แก้ outliers | ปานกลาง | 1-2 ชั่วโมง |
| สร้างฟีเจอร์พื้นฐาน | MA, RSI, ATR, volatility | ปานกลาง | 2-4 ชั่วโมง |
| กำหนดกฎการเทรด | เขียน entry/exit rule แบบง่าย | ต่ำ | 30-90 นาที |
| Backtest เบื้องต้น | รันบนชุดข้อมูลย้อนหลัง | ปานกลาง | 2-6 ชั่วโมง |
| ประเมินผลการทดสอบ | คำนวณ P/L, Drawdown, Win rate | ปานกลาง | 1-3 ชั่วโมง |
| ปรับปรุงสมมติฐาน | แก้ parameter ทีละตัว | สูง | 2-8 ชั่วโมง |
| เริ่มเทรดจริงเล็กน้อย | บัญชีเดโมหรือเงินน้อย | ต่ำ | เริ่มทันที, ทดสอบ 1-3 สัปดาห์ |
การวิเคราะห์โดยย่อ: ตารางนี้แสดงว่าจุดเริ่มต้นไม่ต้องซับซ้อน — ให้เน้นการเชื่อมข้อมูลและการทดสอบแบบแยกส่วนเป็นหลัก เวลาและความยากกระจายไปตามขั้นตอนที่เกี่ยวกับการพัฒนาและการปรับพารามิเตอร์ การลงทุนเวลาในขั้นตอนทำความสะอาดและ Backtest จะลดความผิดพลาดเมื่อเข้าสู่การเทรดจริง
ท้ายสุด ให้มองการเรียนรู้นี้เป็นกระบวนการซ้ำ: ทดสอบ ปรับ ปฏิบัติ แล้วขยายเมื่อสมมติฐานถูกยืนยันแล้วเท่านั้น — วิธีนี้จะปกป้องเงินทุนและสร้างรากฐานที่มั่นคงสำหรับการเทรดที่ยั่งยืน.
ข้อสรุปและขั้นตอนถัดไปสำหรับผู้อ่าน
Big Data ให้มุมมองเชิงปริมาณที่ช่วยเปิดมิติใหม่ในการวิเคราะห์เทรนด์ตลาดฟอเร็กซ์ แต่ไม่ได้รับประกันผลกำไรอัตโนมัติ ความได้เปรียบจริงๆ เกิดจากการจับคู่ข้อมูลคุณภาพกับกระบวนการทดสอบที่เป็นระบบ เริ่มจากการทดลองเล็กๆ แล้วค่อยขยายตามผลที่วัดได้ จะช่วยจำกัดความเสี่ยงและสร้างความเชื่อมั่นก่อนนำไปใช้กับเงินทุนจริง
การวางแนวทางปฏิบัติที่ชัดเจนช่วยเปลี่ยนข้อมูลเชิงปริมาณให้เป็นสัญญาณที่ใช้งานได้จริง
- เริ่มจากข้อมูลคุณภาพ: เลือกแหล่งข้อมูลที่เชื่อถือได้และตรวจสอบการทำความสะอาดข้อมูลก่อนวิเคราะห์
- ทดสอบแบบเป็นขั้นตอน: ทดลองกับ
บัญชีเดโมก่อนเสมอเพื่อแยกสัญญาณจากเสียงรบกวน - วัดผลเป็นระบบ: สร้างตัวชี้วัดที่จับต้องได้ เช่น อัตราการชนะ, อัตรผลตอบแทนต่อความเสี่ยง
- ปรับขนาดตามผลลัพธ์: ขยายขนาดตำแหน่งเฉพาะเมื่อผลจากการทดสอบสอดคล้องกันจริงๆ
ขั้นตอนถัดไปที่แนะนำให้ลองทำ
- เปิด
บัญชีเดโมแล้วตั้งขอบเขตการทดสอบ (เวลา, คู่สกุลเงิน, ขนาดตำแหน่ง) แล้วรันกลยุทธ์อย่างน้อย 30–90 วัน - บันทึกผลทุกรายการในไฟล์สเปรดชีต — วันที่, เวลาเข้าออก, เหตุผลการเข้า, ผลลัพธ์, สถานะอารมณ์ — เพื่อให้การวิเคราะห์ย้อนหลังทำได้ชัดเจน
- วิเคราะห์ผลด้วยมาตรการเชิงคุณภาพและเชิงปริมาณ เช่น การกระจายผลตอบแทน, 最大 drawdown, และค่าเฉลี่ยกำไร/ขาดทุน ต่อจากนั้น ปรับพารามิเตอร์แล้วทดสอบซ้ำ
ตัวอย่างการนำไปใช้จริง: เริ่มด้วยการใช้ Big Data เพื่อระบุช่วงเวลาที่ความผันผวนเพิ่มขึ้น จากนั้นทดสอบกลยุทธ์การจัดการความเสี่ยงที่ปรับตามความผันผวนใน บัญชีเดโม ก่อนจะพิจารณานำไปใช้จริง
หากต้องการเครื่องมือหรือแหล่งทดลอง เริ่มจากการใช้บริการตรวจสอบโบรกเกอร์และบัญชีเดโมที่เชื่อถือได้ เช่น XM เพื่อทดลองแพลตฟอร์มและสภาพการเทรดโดยไม่เสี่ยงเงินจริง
ลงมือทีละขั้น จะช่วยให้ข้อมูลจาก Big Data กลายเป็นเครื่องมือในการตัดสินใจ ไม่ใช่เพียงกราฟที่สวยงามบนหน้าจอ.
สรุป
ถ้ารู้สึกว่าการตีความข่าวรายวันไม่พอ การนำการวิเคราะห์ Big Data มาใช้ช่วยให้เห็นภาพกว้างของสภาพคล่อง ความสัมพันธ์ระหว่างตัวชี้วัด และสัญญาณที่ซ่อนอยู่ในข้อมูลฟอเร็กซ์ ข้อสังเกตจากบทความนี้คือ: เริ่มจากแหล่งข้อมูลที่เชื่อถือได้ก่อน, ตั้งสมมติฐานการทดสอบ และใช้ชุดข้อมูลใหญ่เพื่อยืนยันแนวโน้มแทนการตัดสินใจจากตัวเลขเดียว ตัวอย่างกรณีศึกษาที่ยกมาแสดงให้เห็นว่าเทรดเดอร์ที่จับสัญญาณเทรนด์ตลาดฟอเร็กซ์จากข้อมูลทวิตเตอร์และออเดอร์บุ๊ก สามารถปรับจังหวะเข้าออกได้ดีขึ้นโดยลด false signal ได้อย่างเป็นรูปธรรม ความกังวลเรื่องต้องมีทรัพยากรสูงหรือเขียนโปรแกรมเป็นต้นแบบนั้นแก้ได้ด้วยเครื่องมือสำเร็จรูปและวิธี backtest ขั้นพื้นฐาน
ถัดไปให้ทำสามอย่างชัดเจน: คัดเลือกแหล่งข้อมูลฟอเร็กซ์ที่น่าเชื่อถือ, ออกแบบสมมติฐานแล้ว backtest ก่อนใช้เงินจริง, และ เริ่มด้วยบัญชีทดลองเพื่อเชื่อมต่อเครื่องมือวิเคราะห์ — สำหรับการทดลองและเชื่อมต่อแพลตฟอร์มจริงลอง net/brokers/xm/” target=”_blank” rel=”noopener noreferrer”>เปิดบัญชีกับ XM เพื่อทดลองเทรดและเชื่อมต่อเครื่องมือวิเคราะห์ และหากพร้อมทดสอบกับเงินทุนจำนวนน้อย สามารถพิจารณา ทดสอบบัญชีกับ HFM สำหรับเทรดจริงหลังจากผ่านการ backtest เพื่อพิสูจน์แนวทางก่อนขยับขนาด การเริ่มจากขั้นตอนเล็กๆ เหล่านี้จะช่วยให้การนำข้อมูลขนาดใหญ่มาปรับใช้กับเทรนด์ตลาดฟอเร็กซ์เป็นเรื่องจับต้องได้แล้วนำไปสู่การตัดสินใจที่มีน้ำหนักขึ้นในอนาคต.